
Overview
The Boring Embeddings are negative-control textual inversion embeddings for Stable Diffusion models. They are
widely used in the community (10M+ generations across public tools) to suppress low-quality,
low-engagement visual patterns and make outputs look more visually appealing.
Boring Embeddings Quick Start
These Stable Diffusion embeddings capture what it means for an image to be uninteresting. This is useful because it allows you to instruct your model NOT to produce images that look uninteresting. If you're using the Automatic1111 Stable Diffusion WebUI, just download one of the pt files into your stable-diffusion-webui\embeddings directory and use the embedding's name in your NEGATIVE prompt for more interesting outputs.
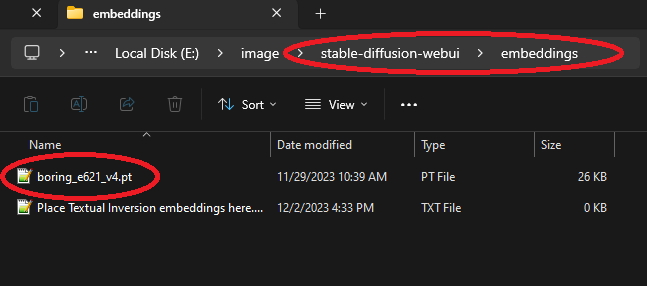 |
 |
| Download a .pt file to stable-diffusion-webui\embeddings | Type the embedding's name (without the .pt extension) in your negative prompt |
Research Summary / Technical Contribution
This project demonstrates a novel approach to constructing negative-control embeddings using automated quality-based sampling
from large community-labeled image datasets. The method avoids hand-curated defect lists and instead captures latent features
correlated with low engagement. Applications include quality control in generative models, aesthetic filtering, and
domain-specific negative conditioning.
Model Description
The motivation for Boring embeddings is that negative embeddings like Bad Prompt, whose training is described here depend on manually curated lists of tags describing features people do not want their images to have, such as "deformed hands". Some problems with this approach are:
- Manually compiled lists will inevitably be incomplete.
- Models might not always understand the tags well due to a dearth of training images labeled with these tags.
- It can only capture named concepts. If there exist unnamed yet visually unappealing concepts that just make an image look wrong, but for reasons that cannot be succinctly explained, they will not be captured by a list of tags.
To address these problems, we employ textual inversion on a set of images extracted from several large community-tagged art
datasets with rich metadata. Each of these sites is a rich resource of millions of
hand-labeled artworks which allow users to express their approval of an artwork by either up-voting it or marking it as a favorite.
The Boring embeddings were specifically trained on artworks automatically selected from these sites according to the criteria
that no user has ever favorited them, and they have 0 or only a very small number of up or down votes. The Boring embeddings
thus learned to produce uninteresting low-quality images, so when they are used in the negative prompt of a stable diffusion image generator,
the model avoids making mistakes that would make the generation more boring.
Each training sample consisted of an image paired with a comma-separated list of all the tags associated with it on the site it was sourced from, with the embedding’s name prepended to the list.
This ensures that the model learns to associate the embedding with the characteristics of uninteresting images in a way that aligns with the dataset’s tagging system.

Usage & Adoption
Boring Embeddings have been adopted across multiple Stable Diffusion communities:
- Downloaded 56k+ times across hosting platforms.
- Integrated into several popular WebUI / workflow presets as a default negative embedding.
- Used in 10M+ image generations (based on platform usage statistics).
Versions
Click to expand the full version list
boring_e621:
- Description: The first proof of concept of this idea. It is less refined than the other versions, but its less-intense effect might still be desirable.
- Training Data Description: A random selection of about 200 several-month-old images from e621.net having 0 favorites, fewer than 10(ish) up or down votes, and not having the tag "comic".
- Model Trained On: YE18.
- Use Case: Legacy. Maybe still useful on Stable Diffusion 1.4 or 1.5-based models if you want a less intense effect.
- Trigger Word: by boring_e621
boring_e621_v4:
- Description: Extends the basic Boring embedding idea with several improvements including:
- Tweaks to how data was selected for inclusion.
- Initialized with text "by <average vector representation of 100 low-scoring e621 artist names>" (which means that you should not have to use the word "by" to trigger it anymore)
- Training Data Description: About 600 several-month-old images from e621.net having 0 favorites and a score of 0. (Comic pages are no longer excluded)
- Model Trained On: YE18.
- Use Case: The most general purpose embedding. Probably the best Boring embedding for most SD 1.4 or 1.5 based models.
- Trigger Word: boring_e621_v4
boring_e621_fluffyrock_v4:
- Description: A version of boring_e621_v4 trained on a different popular model that understands e621 tags.
- Training Data Description: Identical training set to boring_e621_v4.
- Model Trained On: fluffyrock-576-704-832-960-1088-lion-low-lr-e27.
- Use Case: Best for models having Fluffyrock in their ancestry, but might not work well on versions with "v-pred" in the name.
- Trigger Word: boring_e621_fluffyrock_v4
boring_pony_v1:
- Description: A proof of concept using a dataset collected from derpibooru.org and trained on a model that understands derpibooru tags.
- Training Data Description: About 200 several-month-old images from derpibooru.org having 0 favorites, a score of <= 0, and fewer than 5 total up or down votes.
- Model Trained On: Pony Diffusion V4
- Use Case: None yet. It performs better on Pony Diffusion V4 than this model's in-built score-based negative-embedding-like tag (derpibooru_p_low), but less well than boring_e621_v4.
- Trigger Word: boring_pony_v1
boring_sdxl_v1:
- Description: An sdxl embedding hacked together from just boring_e621_fluffyrock_v4 (the clip_l component), and the 0 vector (the clip_g component). Made with this tool.
- Training Data Description: n/a
- Model Trained On: n/a
- Use Case: Works better on Pony Diffusion V6 than on the base sdxl model.
- Trigger Word: boring_sdxl_v1
Bias, Risks, and Limitations
- Using these negative embeddings sacrifices some fidelity to the prompt in exchange for improved overall quality. For example, characters in the image may disappear or change eye/skin color.
- Using these negative embeddings may introduce unexpected or undesired content into the image to make it look less boring.
- Unlike other negative embeddings, the Boring embeddings are not intended to fix problems like extra limbs or deformed hands.
Evaluation
To qualitatively illustrate how well the Boring embeddings have learned to improve image quality, we apply them to a small set of simple sample prompts using the base Stable Diffusion 1.5 model.

As we can see, putting these embeddings in the negative prompt yields a more delicious burger, a more vibrant and detailed landscape, a prettier pharoah, and a more 3-d-looking aquarium. Hyperparameters were tuned based on manual evaluations of grids like these.
Extended Qualitative Evaluation (Paired Comparison Grid)
To supplement the examples shown above, we constructed a larger paired comparison dataset illustrating the embedding’s effect across a broad prompt and seed space.
For this evaluation, we used:
- 10 diverse prompts
- 10 fixed seeds per prompt (0–9)
- Baseline generation vs. generation with the embedding
- Identical sampler, steps, and resolution across all generations
Because each baseline image is paired with an image generated using the same seed, the overall structure and composition remain constant.
This makes the embedding's influence directly visible in latent space, independent of stochastic variation.
A complete grid of all 200 images is available for download here:
➡️ Download the full 200-image comparison grid (136 MB)
{kind=link}
Observed Effects (Qualitative)
Across nearly all prompt/seed pairs, the versions generated with the embedding exhibit:
- increased color vibrancy
- reduced muddiness or haze
- sharper silhouette boundaries
- more appealing lighting
- better subject/background separation
An independent viewer (not involved in the generation process) remarked that the embedding versions were “clearly better” in the majority of comparisons.
This artifact provides a transparent, reproducible demonstration of the embedding’s effect across a wide range of seeds and prompts.