
GLM-Image
👋 Join our WeChat and Discord community
📖 Check out GLM-Image's Technical Blog and Github
📍 Use GLM-Image's API
{kind=link}

Introduction
GLM-Image is an image generation model adopts a hybrid autoregressive + diffusion decoder architecture. In general image generation quality, GLM‑Image aligns with mainstream latent diffusion approaches, but it shows significant advantages in text-rendering and knowledge‑intensive generation scenarios. It performs especially well in tasks requiring precise semantic understanding and complex information expression, while maintaining strong capabilities in high‑fidelity and fine‑grained detail generation. In addition to text‑to‑image generation, GLM‑Image also supports a rich set of image‑to‑image tasks including image editing, style transfer, identity‑preserving generation, and multi‑subject consistency.
Model architecture: a hybrid autoregressive + diffusion decoder design.
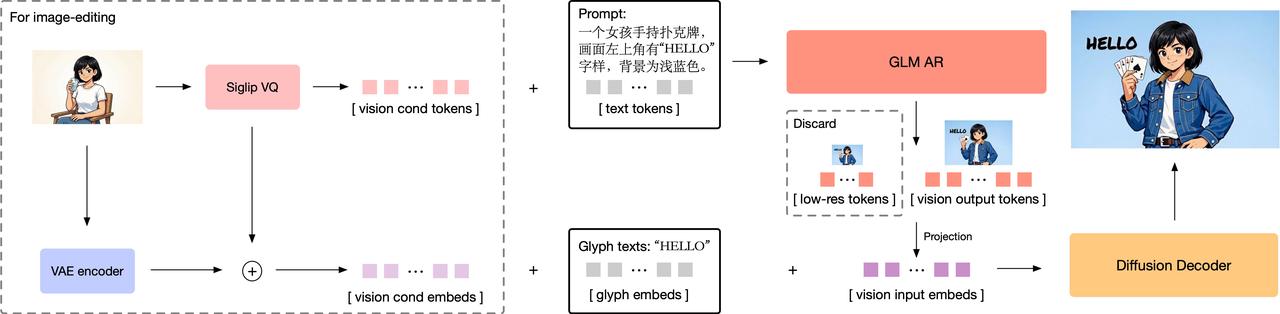
- Autoregressive generator: a 9B-parameter model initialized from GLM-4-9B-0414, with an expanded vocabulary to incorporate visual tokens. The model first generates a compact encoding of approximately 256 tokens, then expands to 1K–4K tokens, corresponding to 1K–2K high-resolution image outputs.
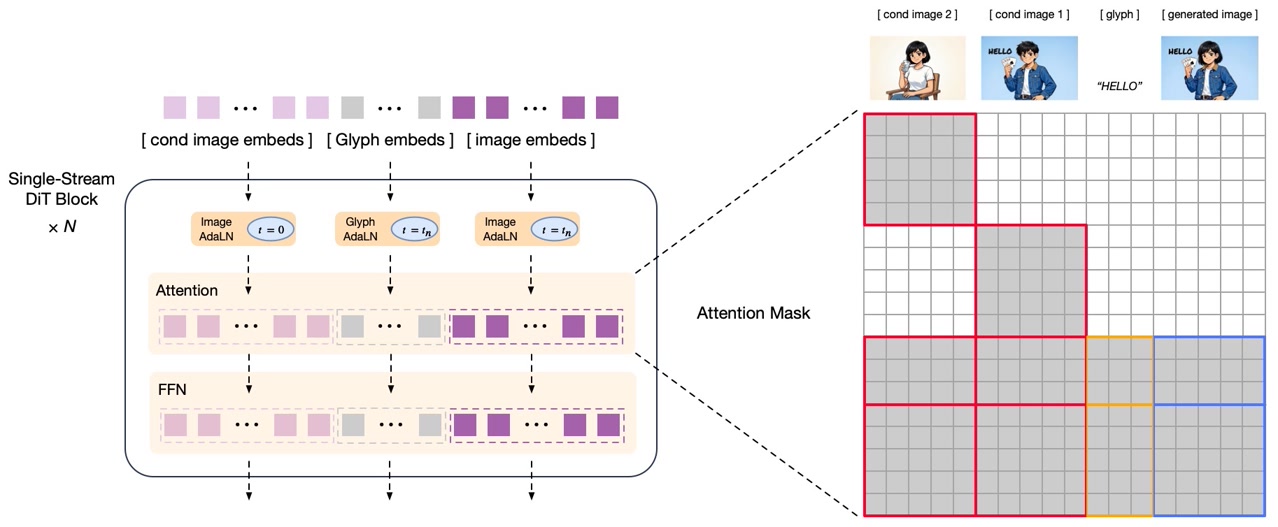
- Diffusion Decoder: a 7B-parameter decoder based on a single-stream DiT architecture for latent-space image decoding. It is equipped with a Glyph Encoder text module, significantly improving accurate text rendering within images.
Post-training with decoupled reinforcement learning: the model introduces a fine-grained, modular feedback strategy using the GRPO algorithm, substantially enhancing both semantic understanding and visual detail quality.
- Autoregressive module: provides low-frequency feedback signals focused on aesthetics and semantic alignment, improving instruction following and artistic expressiveness.
- Decoder module: delivers high-frequency feedback targeting detail fidelity and text accuracy, resulting in highly realistic textures as well as more precise text rendering.
GLM-Image supports both text-to-image and image-to-image generation within a single model.
- Text-to-image: generates high-detail images from textual descriptions, with particularly strong performance in information-dense scenarios.
- Image-to-image: supports a wide range of tasks, including image editing, style transfer, multi-subject consistency, and identity-preserving generation for people and objects.
You can find the full GLM-Image Model implementation in the transformers and diffusers libraries here.
Showcase
T2I with dense text and knowledge

I2I

Quick Start
transformers + diffusers Pipeline
Install transformers and diffusers from source:
pip install git+https://github.com/huggingface/transformers.git
pip install git+https://github.com/huggingface/diffusers.git
- Text to Image Generation
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. The overall layout is clean and bright, divided into four main areas: the top left features a bold black title 'Raspberry Mousse Cake Recipe Guide', with a soft-lit close-up photo of the finished cake on the right, showcasing a light pink cake adorned with fresh raspberries and mint leaves; the bottom left contains an ingredient list section, titled 'Ingredients' in a simple font, listing 'Flour 150g', 'Eggs 3', 'Sugar 120g', 'Raspberry puree 200g', 'Gelatin sheets 10g', 'Whipping cream 300ml', and 'Fresh raspberries', each accompanied by minimalist line icons (like a flour bag, eggs, sugar jar, etc.); the bottom right displays four equally sized step boxes, each containing high-definition macro photos and corresponding instructions, arranged from top to bottom as follows: Step 1 shows a whisk whipping white foam (with the instruction 'Whip egg whites to stiff peaks'), Step 2 shows a red-and-white mixture being folded with a spatula (with the instruction 'Gently fold in the puree and batter'), Step 3 shows pink liquid being poured into a round mold (with the instruction 'Pour into mold and chill for 4 hours'), Step 4 shows the finished cake decorated with raspberries and mint leaves (with the instruction 'Decorate with raspberries and mint'); a light brown information bar runs along the bottom edge, with icons on the left representing 'Preparation time: 30 minutes', 'Cooking time: 20 minutes', and 'Servings: 8'. The overall color scheme is dominated by creamy white and light pink, with a subtle paper texture in the background, featuring compact and orderly text and image layout with clear information hierarchy."
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=50,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
- Image to Image Generation
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32, # Must set height even it is same as input image
width=32 * 32, # Must set width even it is same as input image
num_inference_steps=50,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
SGLang Pipeline
Install transformers and diffusers from source:
pip install "sglang[diffusion] @ git+https://github.com/sgl-project/sglang.git#subdirectory=python"
pip install git+https://github.com/huggingface/transformers.git
pip install git+https://github.com/huggingface/diffusers.git
- Text to Image Generation
sglang serve --model-path zai-org/GLM-Image
curl http://localhost:30000/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"model": "zai-org/GLM-Image",
"prompt": "a beautiful girl with glasses.",
"n": 1,
"response_format": "b64_json",
"size": "1024x1024"
}' | python3 -c "import sys, json, base64; open('output_t2i.png', 'wb').write(base64.b64decode(json.load(sys.stdin)['data'][0]['b64_json']))"
- Image to Image Generation
sglang serve --model-path zai-org/GLM-Image
curl -s -X POST "http://localhost:30000/v1/images/edits" \
-F "model=zai-org/GLM-Image" \
-F "[email protected]" \
-F "prompt=Replace the background of the snow forest with an underground station featuring an automatic escalator." \
-F "response_format=b64_json" | python3 -c "import sys, json, base64; open('output_i2i.png', 'wb').write(base64.b64decode(json.load(sys.stdin)['data'][0]['b64_json']))"
Note
- Please ensure that all text intended to be rendered in the image is enclosed in quotation marks in the model input and We strongly recommend using GLM-4.7 to enhance prompts for higher image quality. Please check our github script for more details.
- The AR model used in GLM‑Image is configured with
do_sample=True, a temperature of0.9, and a topp of0.75by default. A higher temperature results in more diverse and rich outputs, but it can also lead to a certain decrease in output stability. - The target image resolution must be divisible by 32. Otherwise, it will throw an error.
- Because the inference optimizations for this architecture are currently limited, the runtime cost is still relatively high. It requires either a single GPU with more than 80GB of memory, or a multi-GPU setup.
- vLLM-Omni and SGLang (with AR speedup) support is currently being integrated — stay tuned. For inference cost, you can check in our github.
Model Performance
Text Rendering
| Model | Open Source | CVTG-2K | LongText-Bench | ||||
|---|---|---|---|---|---|---|---|
| Word Accuracy | NED | CLIPScore | AVG | EN | ZH | ||
| Seedream 4.5 | ✗ | 0.8990 | 0.9483 | 0.8069 | 0.988 | 0.989 | 0.987 |
| Seedream 4.0 | ✗ | 0.8451 | 0.9224 | 0.7975 | 0.924 | 0.921 | 0.926 |
| Nano Banana 2.0 | ✗ | 0.7788 | 0.8754 | 0.7372 | 0.965 | 0.981 | 0.949 |
| GPT Image 1 [High] | ✗ | 0.8569 | 0.9478 | 0.7982 | 0.788 | 0.956 | 0.619 |
| Qwen-Image | ✓ | 0.8288 | 0.9116 | 0.8017 | 0.945 | 0.943 | 0.946 |
| Qwen-Image-2512 | ✓ | 0.8604 | 0.9290 | 0.7819 | 0.961 | 0.956 | 0.965 |
| Z-Image | ✓ | 0.8671 | 0.9367 | 0.7969 | 0.936 | 0.935 | 0.936 |
| Z-Image-Turbo | ✓ | 0.8585 | 0.9281 | 0.8048 | 0.922 | 0.917 | 0.926 |
| GLM-Image | ✓ | 0.9116 | 0.9557 | 0.7877 | 0.966 | 0.952 | 0.979 |
Text-to-Image
| Model | Open Source | OneIG-Bench | TIIF-Bench | DPG-Bench | ||
|---|---|---|---|---|---|---|
| EN | ZH | short | long | |||
| Seedream 4.5 | ✗ | 0.576 | 0.551 | 90.49 | 88.52 | 88.63 |
| Seedream 4.0 | ✗ | 0.576 | 0.553 | 90.45 | 88.08 | 88.54 |
| Nano Banana 2.0 | ✗ | 0.578 | 0.567 | 91.00 | 88.26 | 87.16 |
| GPT Image 1 [High] | ✗ | 0.533 | 0.474 | 89.15 | 88.29 | 85.15 |
| DALL-E 3 | ✗ | - | - | 74.96 | 70.81 | 83.50 |
| Qwen-Image | ✓ | 0.539 | 0.548 | 86.14 | 86.83 | 88.32 |
| Qwen-Image-2512 | ✓ | 0.530 | 0.515 | 83.24 | 84.93 | 87.20 |
| Z-Image | ✓ | 0.546 | 0.535 | 80.20 | 83.01 | 88.14 |
| Z-Image-Turbo | ✓ | 0.528 | 0.507 | 77.73 | 80.05 | 84.86 |
| FLUX.1 [Dev] | ✓ | 0.434 | - | 71.09 | 71.78 | 83.52 |
| SD3 Medium | ✓ | - | - | 67.46 | 66.09 | 84.08 |
| SD XL | ✓ | 0.316 | - | 54.96 | 42.13 | 74.65 |
| BAGEL | ✓ | 0.361 | 0.370 | 71.50 | 71.70 | - |
| Janus-Pro | ✓ | 0.267 | 0.240 | 66.50 | 65.01 | 84.19 |
| Show-o2 | ✓ | 0.308 | - | 59.72 | 58.86 | - |
| GLM-Image | ✓ | 0.528 | 0.511 | 81.01 | 81.02 | 84.78 |
License
The overall GLM-Image model is released under the MIT License.
This project incorporates the VQ tokenizer weights and VIT weights from X-Omni/X-Omni-En, which are licensed under the Apache License, Version 2.0.
The VQ tokenizer and VIT weights remains subject to the original Apache-2.0 terms. Users should comply with the respective licenses when using this component.
- Downloads last month
- -